Как, надеюсь, вам уже известно в Asterisk`е есть:
- Asterisk Gateway Interface (AGI) — запуск и исполнение любых скриптов на любом языке программирования из dialplan, а так же позволяет выполнять команды dialplan`а в этих скриптах
- Asterisk Manager Interface (AMI) — позволяет «слушать» событие происходящие в Asterisk`е, а так же позволяет выполнять команды
Если вам они неизвестны, то подробнее вы сможете узнать из документации.
Начиная с версии Asterisk`а 12 в нем появился Asterisk REST Interface (ARI), который является воплощением соединения AMI и AGI:
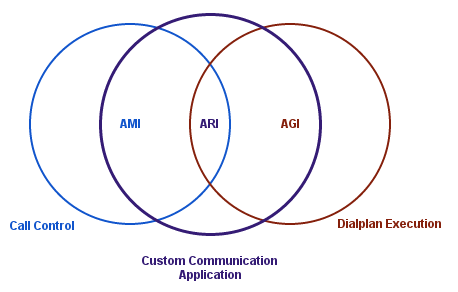
Данные интерфейс позволяет внешнему приложению осуществлять управление вызовом, а так же имеет встроенный Websocket сервер.
Основное в ARI:
- встроенный Websocket сервер
- приложение для dialplan`а именуемое Stasis
- управление вызовом через API
- Websocket сервер передает информацию о происходящих событиях в приложении Stasis
Недавно нам потребовалось реализовать следующую задачу:
Необходимо иметь web-страницу, на которой будут в режиме online отображаться пользователи, которые вошли в конференцию или вышли из нее.
На сервере, где это надо было сделать уже стоял Asterisk 13.6.0
Если необходим online режим, когда страница отображает события происходящие внутри Asterisk непосредственно в момент когда они произошли, Websocket подходит как нельзя лучше.
Мы не использовали ранее ни 12 ни 13-ю версию Asterisk`а и потому опыта работы с ARI у нас до этого момента не было, но понимание принципов работы и применение Websocket на практике уже было. Подробнее о Websocket вы можете узнать на www.websocket.org
Ближе к концу раб. дня ознакомились с немногочисленной документацией и по началу, было очень много вопросов и непоняток, но на следующее утро все, как говорится, встало на свои места. Посему мы решили попробовать реализовать все задуманное используя ARI.
Постараюсь в данной статье изложить суть и озвучить некоторые из вопросов, которые возникали и пояснить некоторые моменты.
Настройка ARI производится в ari.conf. Остановимся на некоторых пунктах настройки, на некоторых потому, что я считаю что не надо объяснять что если вы хотите использовать ARI, то нужно в enabled указывать yes.
allowed_origins — указание URL или URL`ов с которых позволено обращение к Websock`у.
Если указывается несколько URL`ов, то будьте внимательны, они должны разделяться запятой и БЕЗ пробелов.
Пример:
allowed_origins = http://my.domain.ru,http://ari.asterisk.org
Настройки пользователя ARI:
[username]
type = user
read_only = no
password = password
password_format = plain
В read_only указываем yes только в том случае если мы хотим чтобы внешняя система могла только получать уведомления от приложения, но НЕ могла управлять вызовом.
Работа ARI невозможна без встроенного в Asterisk HTTP сервера, а значит для работы нам необходимо его включить — правим настройки в http.conf
После этого заставляем Asterisk перечитать конфигурацию и смотрим на результат своих трудов по настройке:
*CLI> http show status
HTTP Server Status:
Prefix:
Server: AsteriskRU
Server Enabled and Bound to 127.0.0.1:8088
Enabled URI’s:
/httpstatus => Asterisk HTTP General Status
/phoneprov/… => Asterisk HTTP Phone Provisioning Tool
/amanager => HTML Manager Event Interface w/Digest authentication
/arawman => Raw HTTP Manager Event Interface w/Digest authentication
/manager => HTML Manager Event Interface
/rawman => Raw HTTP Manager Event Interface
/static/… => Asterisk HTTP Static Delivery
/amxml => XML Manager Event Interface w/Digest authentication
/mxml => XML Manager Event Interface
/ari/… => Asterisk RESTful API
/ws => Asterisk HTTP WebSocket
Не забудьте, что если вы указывали свой prefix в http.conf, то его необходимо будет использовать во всех URL`ах для обращения. Так же необходимо понимать что помимо ARI становятся доступными и остальные интерфейсы указанные в списке выше. Посему настоятельно НЕ рекомендуется там указывать:
bindaddr=0.0.0.0
Рекомендуется:
bindaddr=127.0.0.1
Итак ARI и WS (Websocket server) запущены. Что далее ? А далее познакомимся с возможностями ARI. Для этого разработчики создали документацию, которая доступна в JSON формате и которую можно получить обратившись на соответствующий URL.
Например: http://localhost:8088/ari/api-docs/resources.json
Если Вы, по отношению к серверу находитесь удаленно, то можно открыть данный URL консольным браузером (например lynx) или сделать проброс порта через SSH. Для этого выполняем:
# ssh myRealAsteriskIP -L8001:127.0.0.1:8088
После чего вы сможете обратиться по URL`у http://localhost:8001/ari/api-docs/resources.json прямо со своего компа.
Все это конечно здорово, но читать доку в Json формате не очень удобно, особенно если в ari.conf вы не указали pretty=yes. Но тут к вам на выручку придут разработчики Asterisk, которые для этих целей создали web-интерфейс ari.asterisk.org, который может подключится к вашему ARI:
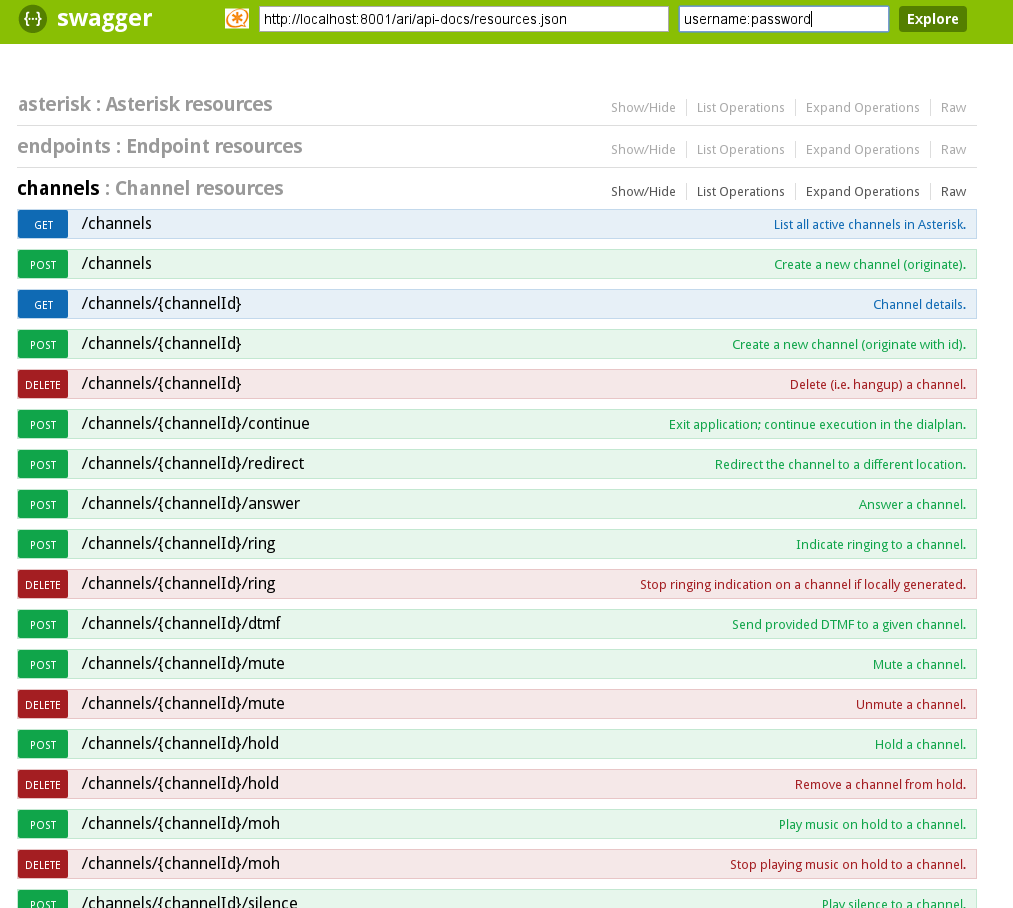
И мы не только можем читать доку по всем командам ARI в удобоваримом виде, но и ПРОБОВАТЬ выполнять ARI команды прямо там же и не отходя от кассы:
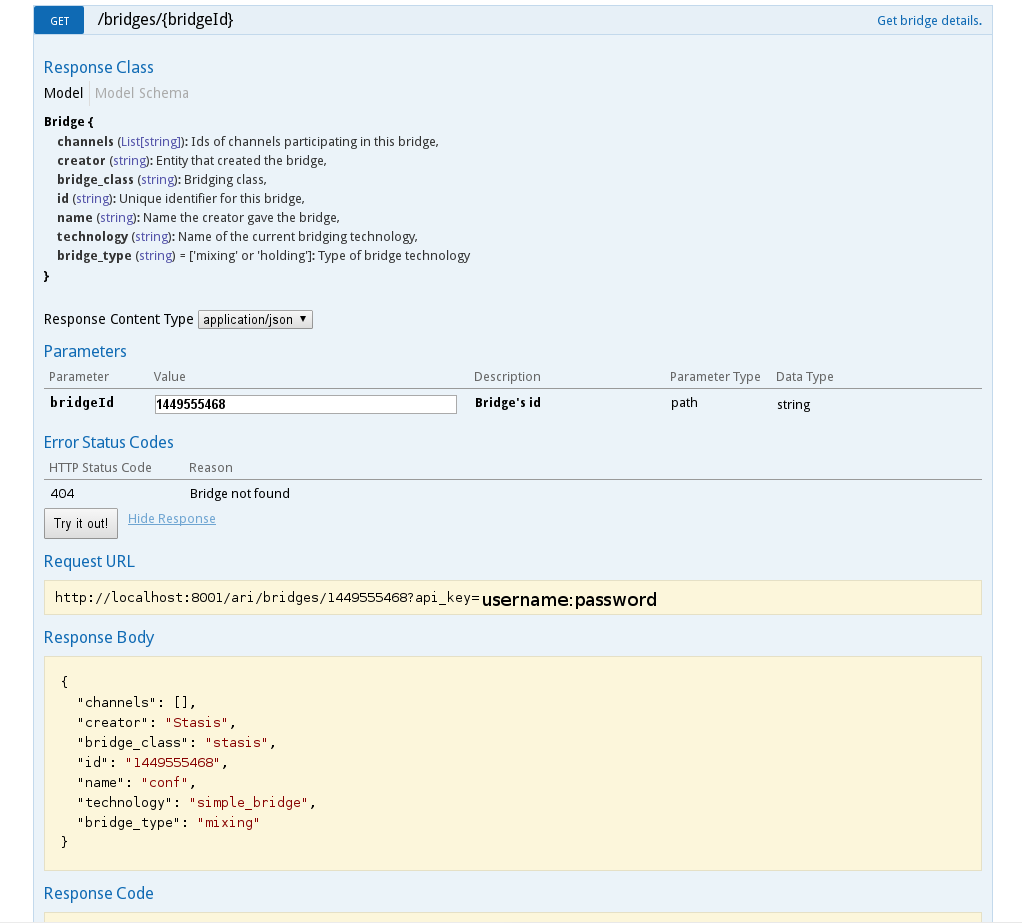
За это разрабам просто низкий поклон и уважуха. Снимаю шляпу перед ними. Если бы этого инструмента не было, то вникать в ARI явно пришлось бы дольше.
Теперь настало время ознакомиться с самим приложением Stasis, чтобы нам было на чем тренироваться в вышеуказанном web-интерфейсе.
Читаем доку:
# asterisk -rx ‘core show application Stasis’
-= Info about application ‘Stasis’ =-
[Synopsis]
Invoke an external Stasis application.
[Description]
Invoke a Stasis application.
This application will set the following channel variable upon completion:
${STASISSTATUS}: This indicates the status of the execution of the Stasis application.
SUCCESS: The channel has exited Stasis without any failures in Stasis.
FAILED: A failure occurred when executing the Stasis The app registry
is not instantiated; The app application. Some (not all) possible reasons
for this: requested is not registered; The app requested is not active;
Stasis couldn’t send a start message.
[Syntax]
Stasis(app_name[,args])
[Arguments]
app_name
Name of the application to invoke.
args
Optional comma-delimited arguments for the application invocation.
Пример применения приложения Stasis в dialplan:
[default]
exten => 1000,1,NoOp()
same => n,Answer()
same => n,Stasis(hello)
same => n,Hangup()
В данном контексте мы наблюдаем вызов приложения Stasis и запуском вашего первого приложения hello, которое будет контролироваться вами через Stasis.
Вот тут стоит обязательно отметить что:
- вы НЕ можете управлять каналом, который находится ВНЕ приложения Stasis
- вы НЕ можете получать события по каналам, которые находятся ВНЕ приложения Stasis
- во время исполнения приложения Stasis исполнение dialplan`а полностью прекращается и если ваше приложение не подает никаких ARI команд, то вызов (канал) будет просто висеть с тишиной в трубке
- если к вашему приложению нет клиентов подключенных по Websocket, то такое приложение работать не будет и вызов (см. пример выше) уйдет по Hangup`у
Давайте ещё раз осознаем, что приложение Stasis позволяет управлять ВАШИМ приложением hello. Тавтология конечно, но не знаю как сказать по иному. Главное чтобы выпонимали разницу между двумя этими приложениями, одно это приложение dialplan`а (Stasis), а другое это ваше приложение (hello (конечно же название приложения может быть любым)).
Если вы все сделали правильно и создали страничку с Websocket`ом и коннектом на ws://127.0.0.1:8001/ws то открыв её вы в CLI увидите:
Activating Stasis app ‘hello’
Это сигнал к тому, что ваше приложение зарегистрировано в системе и вы уже можете приступать к изысканиям 🙂 Начать которые можно путем совершения вызова в контекст и exten где расположен запуск Stasis(hello). В примере выше это контекст default и exten 1000.
Набрав этот номер, как я уже и писал выше, вы ничего не услышите, но воспользовавшись web-интерфейсом вы легко это исправите. Как ?
Кликнем на ветке channels и раскроем первую же вкладку «GET /channels List all active channels in Asterisk», прочтем, вникнем и нажмем магическую кнопку «Try it out!».
После чего web-интерфейс обратиться к ARI по URL`у, который будет указан в «Request URL» и получит оттуда ответ, который будет указан в «Response Body». Если вы ещё не положили трубку, то ответом будет какие каналы сейчас подключены к вашему приложению hello. Далее … а о чем это мы … ах да, о пока тишине в трубке. Исправляем это дело. Копируем номер канала и разворачиваем вкладку «POST /channels/{channelId}/play Start playback of media». В ней вставляем в channelId номер нашего канала и нажмем магическую кнопку «Try it out!».
Можно поступить чуть по другому. ARI может получить команды от вас прямо из консоли сервера. Для этого вам необходим установленный CURL.
Пример команды:
[root@virus ~]# curl -v -u ari_username:ari_password -X POST «http://localhost:8088/ari/channels/1449506765.811/play?media=sound:hello-world»
После чего вы должны услышать в трубке знакомый многим голос, голос штатного приветствия hello-world.wav от Asterisk.
Думаю этих примеров уже достаточно чтобы вы могли начать развлекаться с этим далее уже самостоятельно и потому я не буду приводить других примеров, а перейду к другим важным замечаниям:
Если вы откроете ту же страницу с Websocket`ом с другого компа или просто другим браузером, то в CLI вы увидите:
Replacing Stasis app ‘hello’
== WebSocket connection from ‘XXX.XXX.XXX.XXX:YYYYY’ for protocol » accepted using version ’13’
Activating Stasis app ‘hello’
И после чего первый клиент ПЕРЕСТАНЕТ получат какие либо уведомления от ARI, а из будет получать только второй клиент. Почему так ?
Don’t access ARI directly from a web page
It’s very convenient to use ARI directly from a web page for development, such as using Swagger-UI, or even abusing the WebSocket echo demo to get at the ARI WebSocket.
But, please, do not do this in your production applications. This would be akin to accessing your database directly from a web page. You need to hide Asterisk behind your own application server, where you can handle security, logging, multi-tenancy and other concerns that really don’t belong in a communications engine.
Все это потому, что как вы могли заметить выше:
- в каждой команде к ARI используется apy_key что является парой логин и пароль разделенные двоеточием, который указан в явном виде
- если следовать рекомендациям, то HTTP служба Asterisk`а висит на 127.0.0.1, а это означает что она доступна только локально и соответственно внешний пользователь, который придет на страницу не сможет ничего получать от Websocket сервера
Вот тут мы начинаем осознавать, что без собственно application сервера нам ну никак не обойтись. Что это за зверь ?
Задача application сервера (Websocket сервера) быть подключенным к ARI (зарегистрировать ваше приложение), а так же подключать внешних клиентов и бродкастить им сообщения, которые он получает от ARI. Таким образом вы скроете не только пароль к ARI, но и не позволите ломать вас через остальные интерфейсы, которые предоставляет HTTP служба внутри Asterisk`а.
В кач-ве такого сервера мы остановили свой взор на довольно распространенной платформе nodeJS (Node.js® is a JavaScript runtime built on Chrome’s V8 JavaScript engine)
Именно nodejs может одновременнно выступать в роли сервера для внешних клиентов и в роле клиента по отношению к ARI.
На debian это ставится так:
# apt-get install nodejs
# apt-get install npm
# npm install ws
На FreeBSD нужно поставить порты:
# cd /usr/ports/www/node && make install clean
# cd /usr/ports/www/npm && make install clean
Затем перейти в папку, в которой мы планируем разместить скрипт сервера, например /usr/local/sbin/scripts/ari, и выполнить:
# cd /usr/local/sbin/scripts/ari
# npm install ws
# npm install require
После открываем документацию и вникаем в нее и приводимые там примеры, а так же вот эту документацию, которая вам позволит осознать как обратиться к ARI из JS.
Если вы все осознали, то у вас получится написать js файл, который мы и будем стартовать в кач-ве Websocket сервера из консоли.
Для debian:
# nodejs ws_server.js
Для FreeBSD это:
# node ws_server.js
Самый простой пример Websocket сервера, ws_server.js:
#!/usr/bin/env node
var WebSocket = require('ws');
var WebSocketServer = require('ws').Server;
var request = require('request');
var wss;
wss = new WebSocketServer({ port: 9088 });
wss.on('connection', function connection(server) {
console.log('Web connected');
server.on('message', function incoming(m) {
console.log('received: %s', m);
server.send( m );
console.log('sended: %s', m);
});
});
И если запустить ws_server.js и отправить ему какой либо текст, например «send to websocket server test message«, то мы увидим в консоли
Web connected
received: send to websocket server test message
sended: send to websocket server test message
В заключении:
Именно так мы реализовали исходную задачу. Средствами Stasis была создана конференция, ws_server.js подключается к ARI и регистрирует приложение team, которое обеспечивает создание конференции, проигрывания MOH, mute/unmute и kick, а web-страница все это показывает и позволяет всем этим управлять.
Но это уже материал для другой статьи, которую вероятно я когда нить тоже осилю 🙂
З.Ы. При копировании статьи ссылка на источник ОБЯЗАТЕЛЬНА ! Уважайте чужой труд.
З.Ы.Ы. Наш пример того что получилось можно посмотреть на github.
Автор: Николаев Дмитрий (virus (at) subnets.ru)


 Отправить на почту
Отправить на почту

 (голосов: 3, среднее: 4,67 из 5)
(голосов: 3, среднее: 4,67 из 5)
