Используем BIRD (Internet Routing Daemon) для создания «пограничного» маршрутизатора.
Итак, у нас появилась собственная автономная система и блок /23 PI адресов. Возник вопрос, что использовать для анонсирования своей AS и блока адресов, какое железо?
Клиенты использующие сеть для доступа к Интернет потребляют трафик порядка 300-400Мб/с. Ценник на «железный» роутер для таких задач будет от 400К рублей, поэтому было принято решение — используем opensource и имеющийся в наличии сервер HP Proliant DL140 G3 с двумя 2-х ядерными процессорами и 2Гб оперативной памяти. Используемая ОС — CentOS 5, а в качестве демона маршрутизации был выбран, после некторых тестов и сравнений, —
BIRD. На используемом сервере установлена версия 1.2.4 (процесс установки описан
здесь).
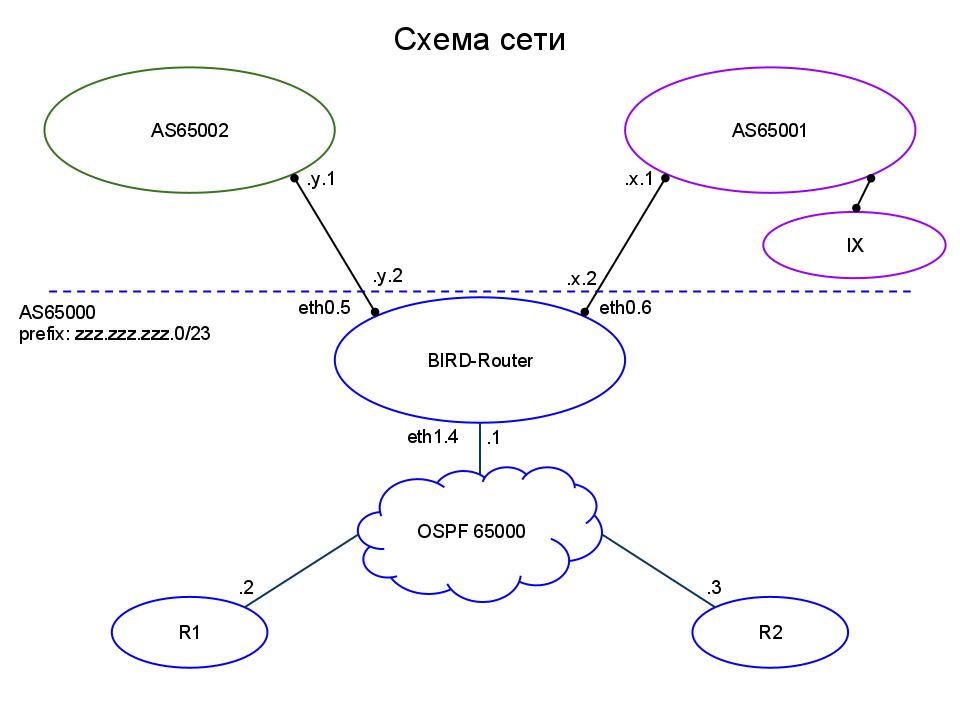
Описание схемы сети.
Смотрим рисунок. Сеть подключается через наш «пограничный» маршрутизатор к двум провайдерам, один из них
AS65002 — основной, второй
AS65001 — резервный, со вторым очень дружественные взаимоотношения и он по доброте душевной бесплатно транзитит наш трафик на точку обмена трафиком и обратно, таким образом, мы немного (а иногда и 50%) экономим на оплате трафика основному провайдеру. Наша AS —
AS6500 и полученный префикс —
zzz.zzz.zzz.0/23. Внутри нашей AS работает протокол
OSPF (выбран исходя из того, что роутеры на базе opensource в сети будут появляться чаще, чем роутеры Cisco). От обоих провайдеров мы получаем
full-view. Дополнительно, второй провайдер (
AS65001) «красит» маршруты с точки обмена трафиком с помощью community —
65001:1400. Для того, чтобы избежать ошибок с получением маршрута по умолчанию от провайдеров, мы сами его с пограничного маршрутизатора объявляем внутрь сети (тем самым, кстати гарантируем, что трафик на несуществующие префиксы не будет уходить дальше нашего роутера). Стыковая сеть с провайдером
AS65002 — y.y.y.0/30, стыковая сеть с провайдером
AS65001 — x.x.x.0/30. Внутри сети между роутерами используется сеть
z.z.z.0/28.
Подготовка к созданию конфигурации BIRD, коротко о BIRD.
С документацией по использованию BIRD можно ознакомиться здесь. Самое основное в понимании работы с BIRD — это представление о таблицах маршрутизации и протоколах, которые работают с этими таблицами. BIRD поддерживает работу протоколов BGPv4, RIPv2, OSPFv2, OSPFv3 и виртуального протокола Pipe для обмена маршрутами между различными таблицами маршрутизации. Для всех протоколов реализована работа с IPv6. Между таблицей маршрутзации и протоколом устанавливаются два фильтра export и import, которые могут принимать, блокировать или изменять получаемую и передаваемую информацию из таблицы в протокол и обратно. Export — направление от таблицы к протоколу, import — в обратную сторону. Когда маршрут передается из протокола в таблицу, его стоимость пересчитывается и об этом оповещаются все протоколы, которые используют данную таблицу, после чего каждый протокол формирует update и рассылает сообщение согласно своему механизму оповещения об изменении маршрута. По-умолчанию в BIRD существует таблица master, которая может использоваться всеми протоколами, если иное в конфигурации протокола не было указано. Кроме указанных выше протоколов, есть еще псевдопротокол kernel, отчечающий за синхронизацию между таблицами маршрутизации BIRD и ядра системы, протокол static — отвечающий за статическую маршрутизацию, протокол direct — создающий маршруты в BIRD на основе настроек сетевых интерфейсов полученных из ядра, и протокол device, отслеживающий состояниме интерфефсов в системе (up/down).
Составим список протоколов и их названий, которые мы будем использовать:
-
bgpAS65002 (в BIRD для работы с bgp соседом необходмо запустить отдельную «ветку» протокола) — для работы с основным провайдером;
-
bgpAS65001 — для работы с резервным провайдером;
-
ospfAS65000 — для обеспечения маршрутизации внутри сети;
-
static1 — понадобится для объявления маршрута по-умолчанию;
-
static2 — используем для объявления нашего «большого» префикса;
-
kernel — понадобится для передачи маршрутов из BIRD в систему;
-
direct и device — их назначение описано выше.
Т.к. конфигурация сети у нас довольно простая, будем использовать только одну таблицу маршрутизации — master.
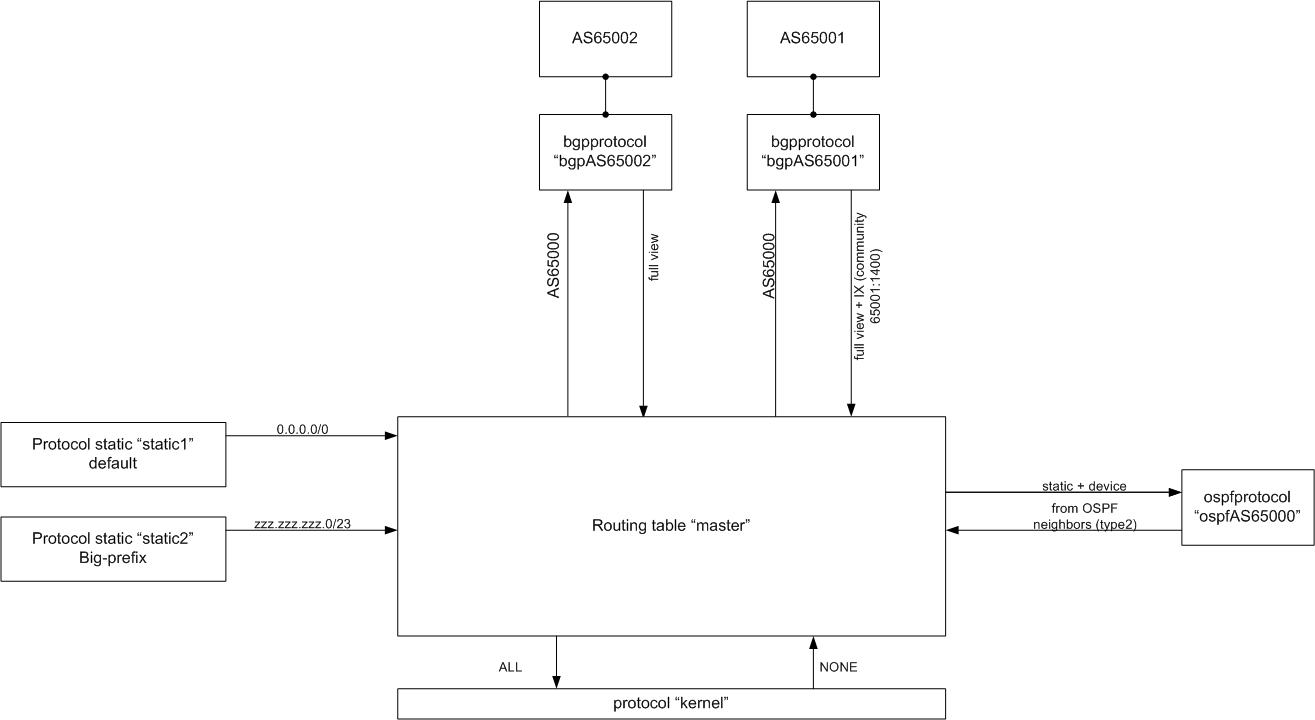
Для составления конфигурационного файла, лучше все взаимосвязи сначала отразим на схеме:
На схеме видно, что нам для работы с информацией из таблицы master и из протоколов потребуются фильтры. Мы их опишем уже непосредственно в конфиге BIRD.
Файл конфигурации BIRD.
/*
* This is an example configuration file.
*/
#Задаем формат времени для логирования
timeformat base iso long;
timeformat log iso long;
timeformat protocol iso long;
timeformat route iso long;
#Указываем путь к лог-файлу
log «/var/log/bird.log» all;
log stderr all;
##### Начнем описание наших протоколов, некоторые описания взяты из дефолтного конфига
# The direct protocol automatically generates device routes to
# all network interfaces. Can exist in as many instances as you wish
# if you want to populate multiple routing tables with device routes.
protocol direct {
interface «eth*», «*»; # Restrict network interfaces it works with
}
# This pseudo-protocol watches all interface up/down events.
protocol device {
scan time 10; # Scan interfaces every 10 seconds
}
# This pseudo-protocol performs synchronization between BIRD’s routing
# tables and the kernel. If your kernel supports multiple routing tables
# (as Linux 2.2.x does), you can run multiple instances of the kernel
# protocol and synchronize different kernel tables with different BIRD tables.
protocol kernel {
persist off; # Don’t remove routes on bird shutdown
scan time 20; # Scan kernel routing table every 20 seconds
import none; # Default is import all
export all; # Default is export none
}
#Статический маршрут, необходимый для добавления маршрута по-умолчанию в таблицу master
protocol static static1 {
route 0.0.0.0/0 via «lo»;
}
#Статический маршрут для добавления нашего префикса в таблицу
protocol static static2 {
preference 253;
route zzz.zzz.zzz.0/23 via «lo»;
}
###Конфигурация протокола OSPF:
#Как мы описывали выше, мы должны объявить нашим ospf соседям маршрут по-умолчанию и маршруты типа directly, а в таблицу master должны передать маршруты полученные от ospf соседей, кроме дефолта
#для этого используем соответствующие фильтры:
filter import_OSPF {
if ( source = RTS_OSPF && net != 0.0.0.0/0 ) then {
print «net accepted:», net;
accept;
}
reject;
}
filter export_OSPF {
#Передаем маршруты connected
if ( source = RTS_DEVICE ) then {
print «net accepted:», net;
ospf_metric2 = 20;
accept;
}
#Передаем маршрут по умолчанию, т.к. он у нас «завернут» на интефрейс loopback, то необходимо использовать конструкцию RTS_STATIC_DEVICE, а не RTS_STATIC
if ( source = RTS_STATIC_DEVICE && net = 0.0.0.0/0 ) then {
print «net accepted:», net;
ospf_metric2 = 5;
accept;
}
reject;
}
#Конфигурация протокола OSPF
protocol ospf ospfAS65000 {
router id 87.244.8.18;
export filter export_OSPF;
import filter import_OSPF;
area 0.0.0.0 {
interface «eth1.4» {
hello 10;
retransmit 5;
cost 10;
transmit delay 1;
dead count 4;
wait 40;
type broadcast;
priority 0;
};
};
}
###
###Настройка BGP
#Задаем функцию, с помощью которой мы будем блокировать сети RFC1918, дефолт, префиксы короче /24, префиксы /32, /0 и /7, если они вдруг «прилетят» от bgp соседей
function avoid_nonexist()
#Описываем префикс-лист, по которому будет происходить проверка маршрутов
prefix set nonexist;
{
nonexist = [ 169.254.0.0/16+, 172.16.0.0/12+, 192.168.0.0/16+, 10.0.0.0/8+, 224.0.0.0/4+, 240.0.0.0/4+, 0.0.0.0/32-, 0.0.0.0/0{25,32}, 0.0.0.0/0{0,7} ];
if net ~ nonexist then return false;
return true;
}
#Задаем функцию, с помощью которой будем фильтровать маршруты из нашей AS
function pref_from_myasset()
prefix set pref_from_65000;
{
pref_from_65000 = [ zzz.zzz.zzz.0/23 ];
if net ~ pref_from_65000 then return true;
return false;
}
###Основной провайдер
##Отфильтровываем маршруты и устанавливаем local preference
filter prov65002in {
if avoid_nonexist() then
{
bgp_local_pref = 340; #устанавливаем local preference
accept;
}
reject;
}
filter prov65002out {
if pref_from_myasset() then
{
bgp_community = -empty-; #не отправляем никаких коммьюнити
bgp_path.prepend(65000); #добавляем prepend
accept;
}
reject;
}
protocol bgp bgpAS65002 {
table master;
router id yyy.yyy.yyy.2;
description «AS65002»;
local as 65000;
neighbor yyy.yyy.yyy.1 as 65002;
hold time 240;
startup hold time 240;
connect retry time 120;
keepalive time 80;
start delay time 5;
error wait time 60, 300;
error forget time 300;
next hop self;
path metric 1;
default bgp_med 0;
source address yyy.yyy.yyy.2;
export filter prov65002in;
import filter prov65002out;
}
###
###Резервный провайдер
##Отфильтровываем маршруты, устанавливаем local preference для маршрутов помеченных community на стороне второго провайдера
filter prov65001in {
if (65001,1400) ~ bgp_community then
{
bgp_local_pref = 400; # local preference для маршрутов отмеченных community 65001:400
accept;
}
bgp_local_pref = 330; #local preference для остальных маршрутов
if avoid_nonexist() then accept;
}
filter prov65002out {
if pref_from_myasset() then
{
bgp_community = -empty-;
accept;
}
reject;
}
protocol bgp bgpAS65001 {
table master;
router id xxx.xxx.xxx.2;
description «AS65001»;
local as 65000;
neighbor xxx.xxx.xxx.1 as 65001;
hold time 240;
startup hold time 240;
connect retry time 120;
keepalive time 80;
start delay time 5;
error wait time 60, 300;
error forget time 300;
next hop self;
path metric 1;
default bgp_med 0;
source address xxx.xxx.xxx.2;
export filter prov65002out;
import filter prov65002in;
}
###
/*
* The End
*/
Для проверки работы фильтров, состояния протоколов, маршрутов и т.п. в BIRD есть свой CLI:
# /usr/local/sbin/birdc
BIRD 1.2.4 ready.
bird> >?
configure [soft] [«<file>»] Reload configuration
debug … Control protocol debugging via BIRD logs
disable <protocol> | «<pattern>» | all Disable protocol
down Shut the daemon down
dump … Dump debugging information
echo [all | off | <mask>] [<buffer-size>] Configure echoing of log messages
enable <protocol> | «<pattern>» | all Enable protocol
exit Exit the client
help Description of the help system
mrtdump … Control protocol debugging via MRTdump files
quit Quit the client
reload <protocol> | «<pattern>» | all Reload protocol
restart <protocol> | «<pattern>» | all Restart protocol
restrict Restrict current CLI session to safe commands
show … Show status information
На этом пока все, буду рад, если эта статья кому-то пожет в работе))
З.Ы. При копировании статьи ссылка на источник ОБЯЗАТЕЛЬНА ! Пожалуйста, уважайте чужой труд.
Автор: zaikini


 Отправить на почту
Отправить на почту