Интеграция Asterisk и Telegram
На одном из форумов посвященных Asterisk`у в очередной раз подняли тему «Как не терять звонки». Тему о том как уведомлять, себя любимого, да и не только себя, о пропущенных вызовах и/или совершенной переадресации. И в очередной раз был предложен метод с использованием СМС. Но ведь есть и другой способ, который на мой взгляд лучше — Telegram.
Почему Telegram ? Потому, что данный мессенджер удобен и у него много приятных фишек, например таких как боты.
Собственно с помощью бота можно не только отправлять себе что-то, но и получить обратную связь.
У нас уже был опыт подобной связи и мы уже использовали эту возможность для соединения нашего чата с Telegram, дабы иметь возможность общаться не только сидя перед компом.
Итак далее про интеграцию Asterisk и Telegram.
Чтобы показать пример отправки сообщения в Telegram я по быстрому зарегистрировал нового бота и создал небольшой PHP скрипт, который расположил тут: http://bot.subnets.ru/telegram/
Принцип работы такой:
После чего наблюдаем отправленный вами текст на экране своего смартфона/компа.
Таким образом используя вAsterisk функцию CURL и/или другой скрипт вызываемый с помощью функции System, или AGI скрипт, вообщем все то что может обратиться к URL, мы можем отправлять себе сообщения прямо из dialplan Asterisk или консоли сервера.
И вот тут у меня проснулся интерес. Отправлять сообщения конечно здорово, но иметь обратную связь с Asterisk будет ещё лучше.
Как эту обратную связь использовать ? Да первое что мне пришло на ум это callback. Тыкаем в команду бота и тут же получаем callback от своего Asterisk.
Здорово, но мало 🙂 А что если реализовать возможность отправлять в Asterisk команды CLI прямо из Telegram и получать вывод этих команд ? Да, было бы не лишним.
Почему не лишним ? Да потому что ты не все время у компа и если вдруг что-то пойдет не так и тебе позвонят с работы «Ой, все упало !», то подобная прямая связь с Asterisk была бы кстати, т.к. очень быстро готова к использованию и прямо с мобилы.
Потратив некоторое время на разработку функционала самого бота и написав PHP клиента для связи с Asterisk я все же добился необходимого мне результата.
Я смог выполнить произвольную команду в CLI Asterisk. На скриншоте ниже это выполнение команды core show calls:
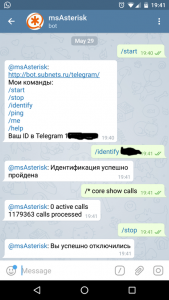
Asterisk и Telegram
Ну или даже вот так:
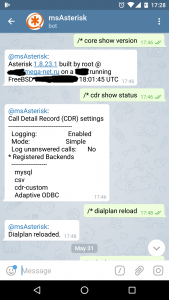
Asterisk и Telegram
Вот такой получился интересный, на мой взгляд, проект.
Для скептиков:
Функции защиты всего это добра от использования сторонними людьми предусмотрены:
- привязка к конкретному Telegram ID
- идентификация по паролю в самом боте
- контрольная подпись при отправке/получении данных между ботом и PHP клиентом
- возможность ограничить доступ к PHP клиенту по IP-адресам
- возможность указать какие команды Asterisk CLI будут доступны для исполнения
P.S. Если Вы так же хотите попробовать покомандовать своим Asterisk через Telegram, то я могу предоставить Вам такую возможность.
Для этого Вам будет необходимо:
- ваше желание тестировать и сообщать об ошибках
- иметь свой сервер с Asterisk
- иметь установленный PHP (не ниже версии 5.6)
- запущенный HTTP сервис (например apache), до которого можно достучаться извне
- обратиться ко мне ( virus [СОБАЧКА-ГАВ-ГАВ] subnets.ru ) для получения паролей и явок 🙂
- скачать и настроить PHP клиента для связи с Вашим Asterisk (PHP клиент НЕ обязательно должен быть расположен на сервере с Asterisk, он может находится и отдельно (например на Вашем WEB сервере))
- выполнить настройки HTTP службы в Asterisk
P.S.S. При копировании статьи ссылка на источник ОБЯЗАТЕЛЬНА ! Уважайте чужой труд.
Автор: Николаев Дмитрий (virus (at) subnets.ru


 Отправить на почту
Отправить на почту




