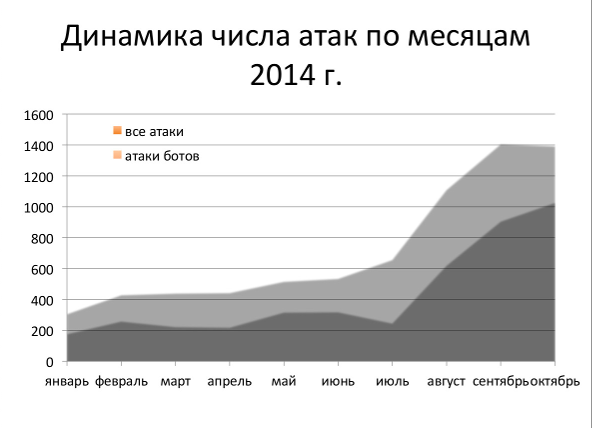
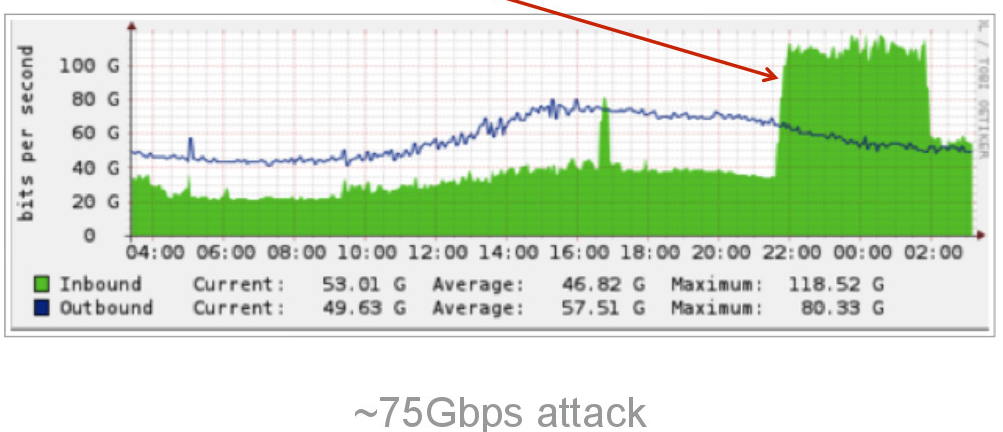
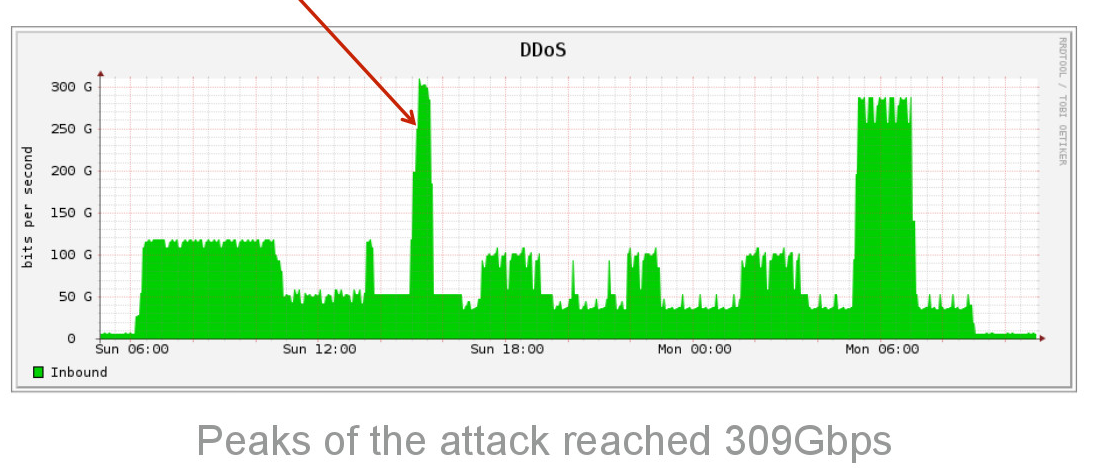
10 декабря прошел очередной (уже 11-ый) пиринговый форум MSK-IX и я снова был одним из участников данного форума.
К сожалению в этот раз программа форума никак не затрагивала глобальную проблему DDoS`а как это было на прошлом форуме и как мне кажется это очень зря, т.к. необходимо обращать внимание участников на данную проблему и совместно бороться с этим. Эта проблема ведь никуда не делась, она осталась.
Чтобы я хотел отметить так это «BGP: к лучшему протоколу и практикам. Неформальная рабочая группа.» в которой я поучаствовал.
В рамках беседы обсуждалась проблема с которой многие уже сталкивались, а именно bgp route leaks. Проблема которая периодически возникает по вине новичков. Тех кто настраивает BGP впервые и зачастую не читая какой либо документации, а лишь какую либо статью на просторах тырнета. Так же снова обсуждался проект MANRS (Mutually Agreed Norms for Routing Security) и звучали призывы присоединиться к данному проекту.
![]()
Mutually Agreed Norms for Routing Security (MANRS)
Данный проект преследует цели объединения IT сферы в соблюдении простых правил:
- Filtering: Предотвращение распространения неправильной маршрутной информации
- Anti-spoofing: Предотвращение трафика с подложными IP-адресами
- Coordination: Содержание контактной и иной информации в up-to-date
- Global Validation: Улучшение информационного обмена и координации между сетевыми операторами в глобальном масштабе
Соблюдение провайдерами и их пользователями данных правил позволит сократить многие проблемы, как то DDoS или BGP route leaks.
Автор проекта Андрей Робачевский уверен в том, что чем больше организаций поучаствуют в данном проекте, подпишутся под MANRS Document и будут соблюдать его тем больше новичков обратят на него внимание. Я не совсем согласен с ним в той части, что это обратит внимание новичков на эти пункты, т.к. скорее всего они даже не увидят данного документа и уж тем более не выполнят озвученные в нем пункты, а если даже увидят, то вряд ли прочтут (документацию то они не читают, к ОГРОМНОМУ сожалению конечно), но я абсолютно согласен с ним в той части, что необходимо хотя бы пытаться что-то с этим делать. Делать надо уже давно и делать уже сейчас, т.к. потом может стать уже слишком поздно и наши маршрутизаторы и каналы будут забиты только DDoS трафиком.
Потому я решил снова написать об этом проекте и просить вас, читателей данной статьи, обратить внимание на соответствие ваших сетей простым правилам данного проекта и если у вас есть «пробелы», то устранить их на вашей сети. Глядишь кол-во ботов и DDoS атак сократиться.
Александр Азимов из Qrator Labs (создатели QRATOR RADAR MONITOR о котором я так же писал в прошлый раз) предложил внести правки в прокол BGP — проект «A Simple BGP«.
Вкратце озвучу суть предлагаемых изменений. Они состоят в том, чтобы попытаться вовсе искоренить проблему BGP route leak. Проблему которая возникает из-за новичков, которые при настройке BGP сессии указывают лишь IP-адрес BGP соседа и его ASку и имеют несколько BGP сессий. Да, да, да — такие есть и их много:
Предлагается добавить понятие «роль» в настройки BGP сессии и передавать её в OPEN сообщении, а так же автоматической фильтрации по маркерам основываясь на установленной, в конфигурации, роли.
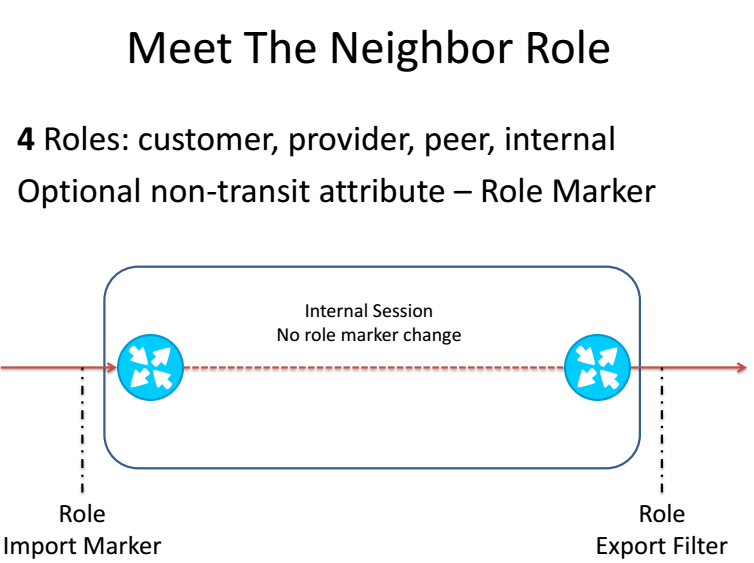
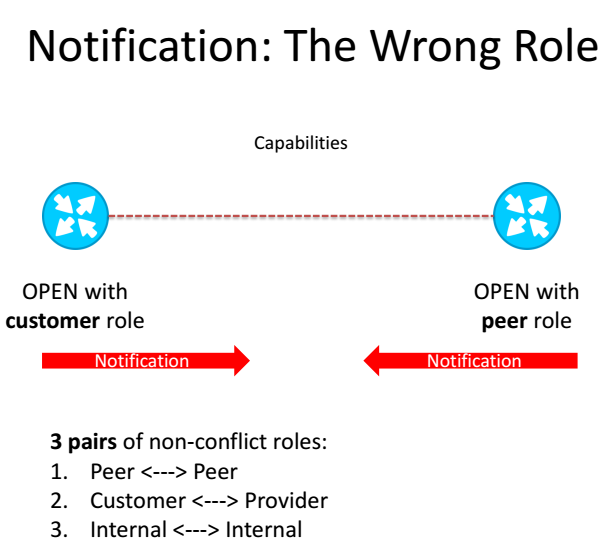
Соответственно если «роли» не совпадут, то BGP соединение не установится и у вас будет повод обратить внимание вашего клиента на НЕ верную конфигурацию на его стороне, а так же если новичок совсем не сделает никак BGP фильтров, то ПО сделает это автоматически и за него.
Считаю что предложение очень здравое и это действительно помогло бы в борьбе (с озвученной выше) с проблемой.
Пожалуй, это все, что я хотел бы сказать по итогам пирингового форума в этом году.
Автор: Николаев Дмитрий (virus (at) subnets.ru)
 (Еще не голосовали)
(Еще не голосовали) Отправить на почту
Отправить на почту